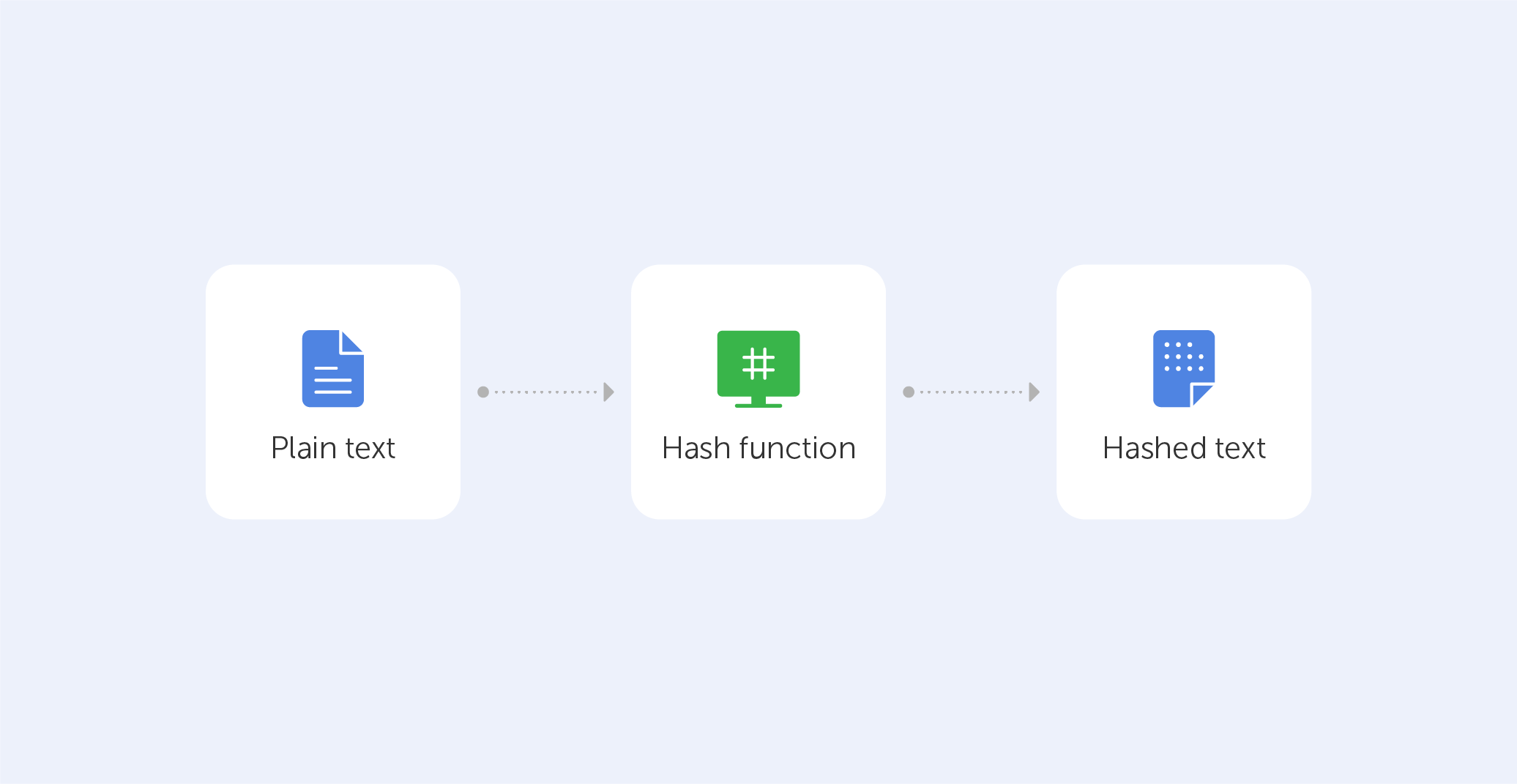
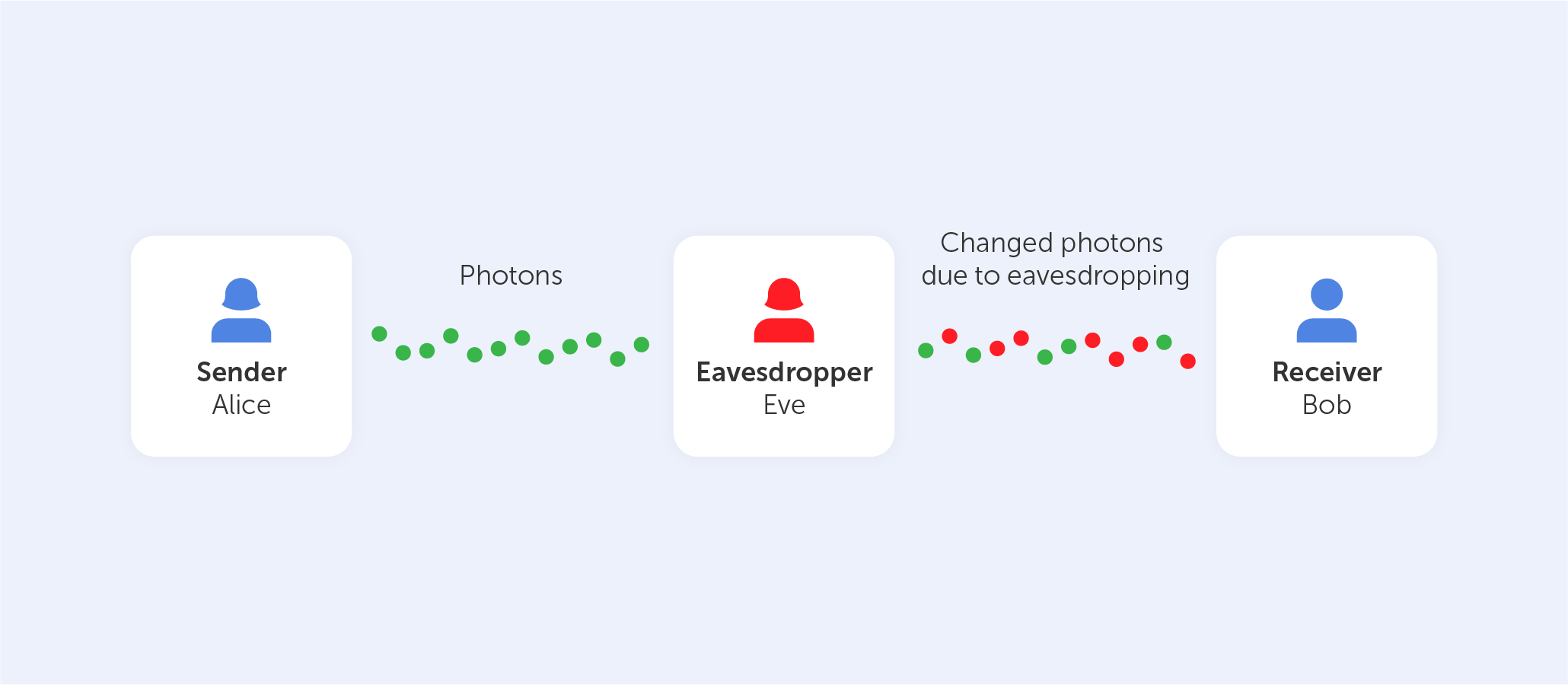
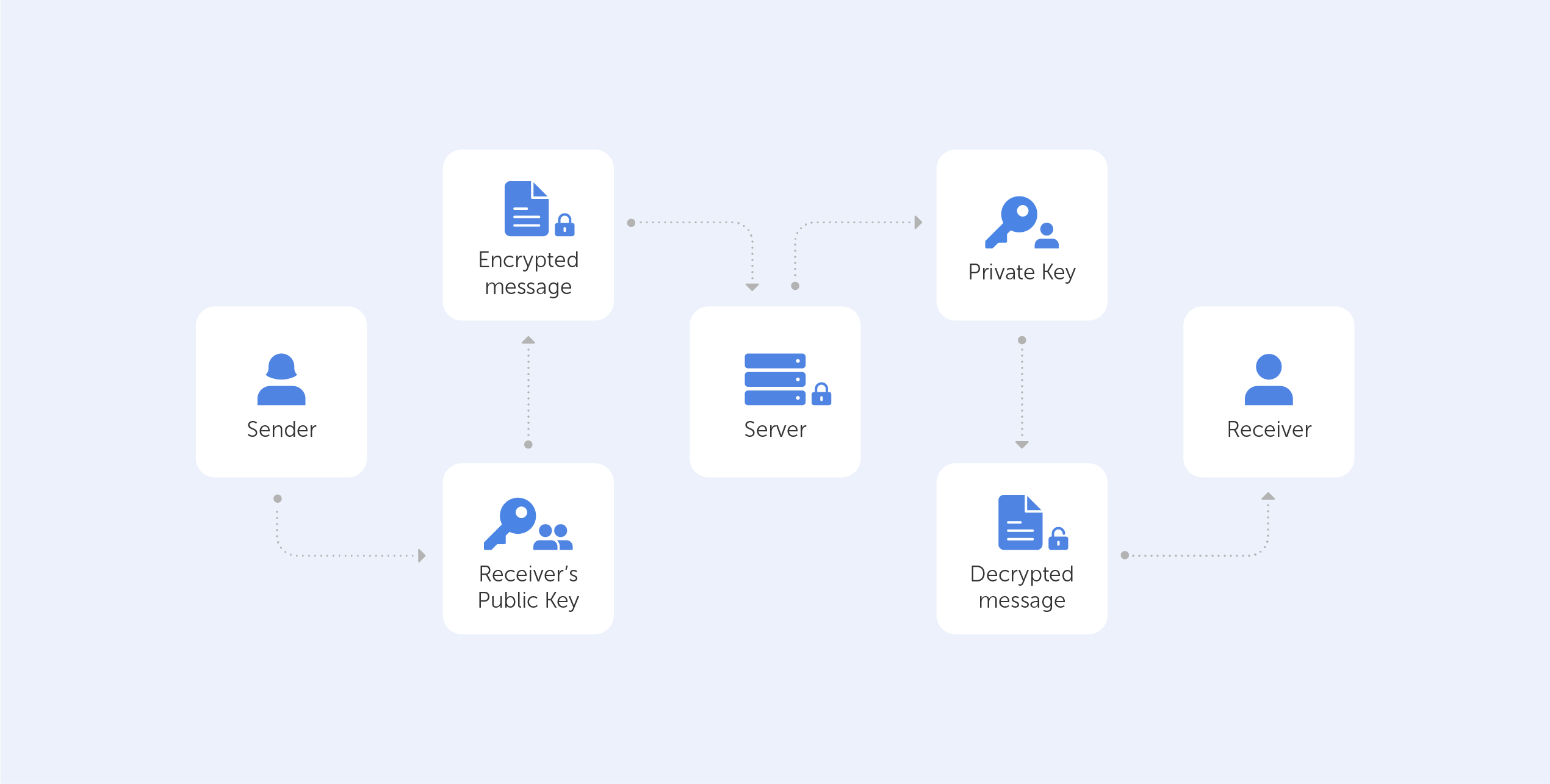
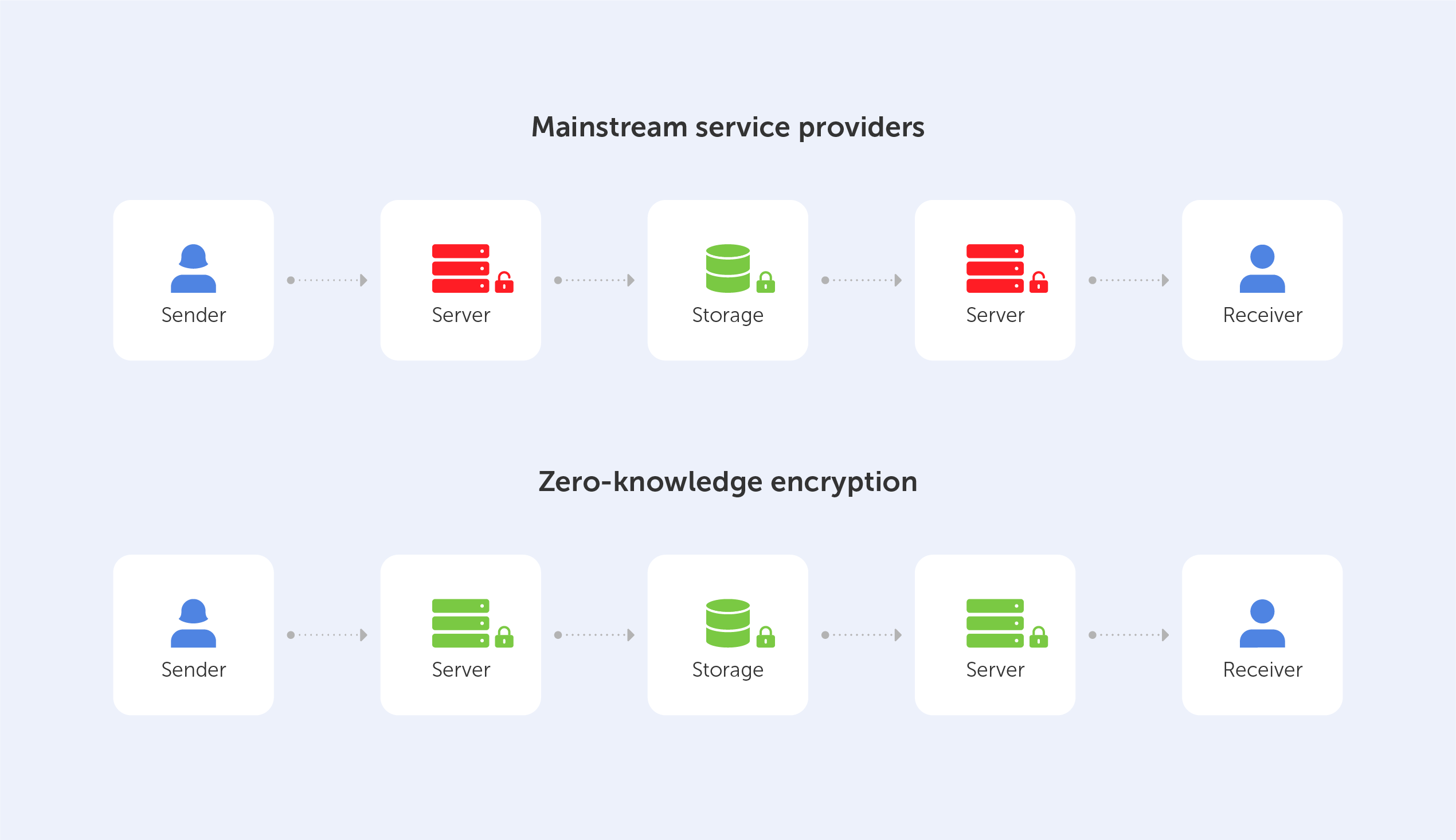
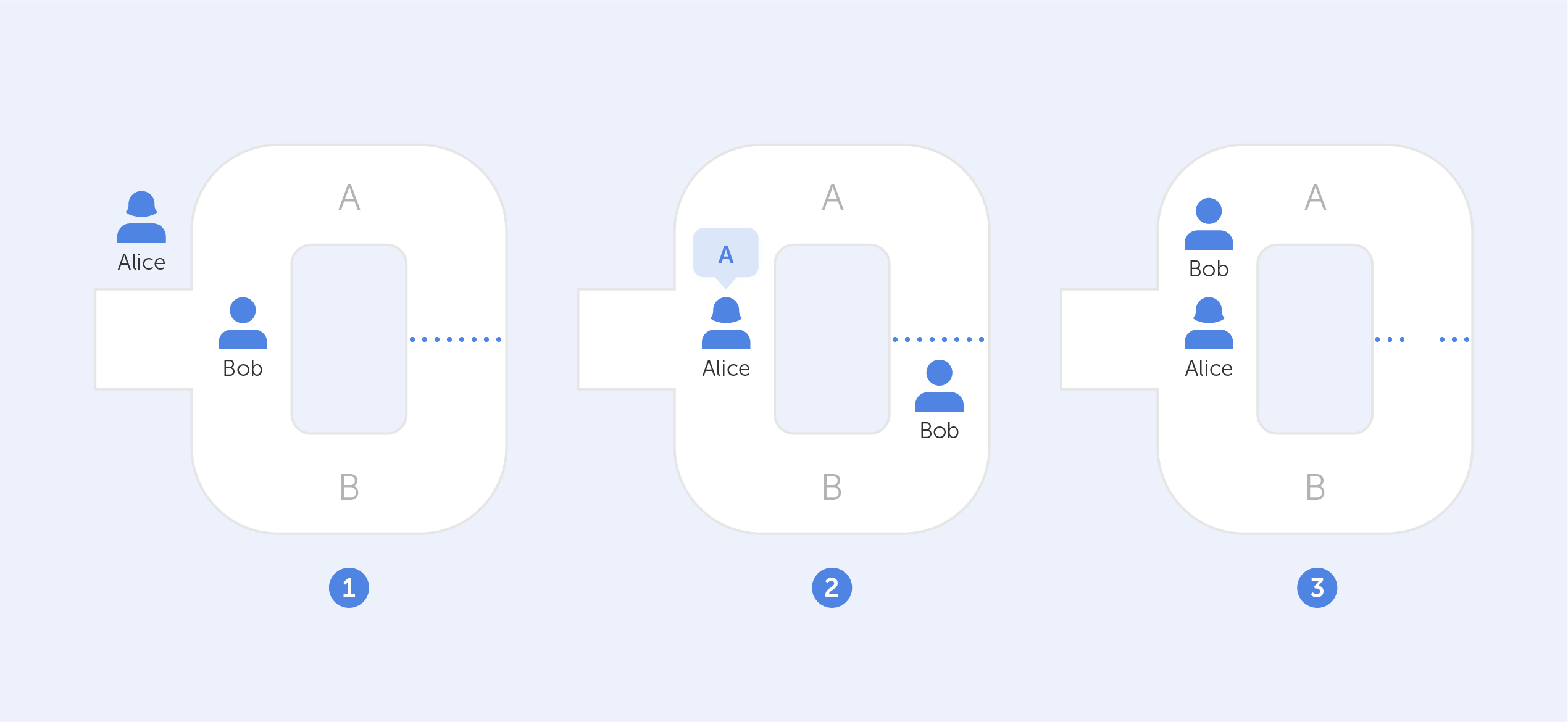
Symmetric algorithms, forming the backbone of modern cryptography, offer a secure method of encrypting and decrypting data utilizing a single shared key. They have been widely adopted for their unmatched speed and efficiency. Like any other technology, symmetric algorithms come with their own set of benefits and drawbacks. This article seeks to offer a comprehensive review of the pros and cons of symmetric algorithms, providing a deeper understanding of their integral role in data security and the potential challenges they entail.
Pros of symmetric algorithms
Unrivaled efficiency
Symmetric algorithms are best known for their superior efficiency in handling large volumes of data for encryption and decryption. The use of a single key significantly reduces the demand for computational resources, setting symmetric algorithms apart from their asymmetric counterparts. This makes them an excellent fit for applications that demand high-speed data processing, including secure communication channels and real-time data transfers.
Impressive speed
Symmetric algorithms, by virtue of their simplicity, can process data at a much faster rate than asymmetric algorithms. Without the need for complex mathematical operations, such as prime factorization or modular arithmetic, symmetric algorithms can encrypt and decrypt data rapidly, reducing latency. This speed advantage is particularly beneficial for applications requiring swift data encryption, including secure cloud storage and virtual private networks (VPNs).
Key distribution
Symmetric algorithms simplify the key distribution process. Given that both the sender and receiver utilize the same key, they only need to execute a secure key exchange once. This offers increased convenience in scenarios where multiple parties need to communicate securely, such as within large organizations, military operations, or corporate communications.
Computational simplicity
Symmetric algorithms are relatively straightforward to implement due to their computational simplicity. This allows for efficient coding, making them ideally suited for resource-constrained devices that possess limited computational capabilities, such as embedded systems or Internet of Things (IoT) devices. This simplicity also contributes to easier maintenance and debugging, reducing the potential for implementation errors that could compromise security.
Cons of symmetric algorithms
Complex key management
The management and distribution of shared keys are significant challenges inherent to symmetric algorithms. The security of these algorithms is closely tied to the confidentiality of the key. Any unauthorized access or compromise of the key can lead to a total breach of data security. Consequently, robust key management protocols are essential, including secure storage, key rotation, and secure key exchange mechanisms, to mitigate this risk.
Lack of authentication
Symmetric algorithms do not inherently provide authentication mechanisms. The absence of additional measures, such as digital signatures or message authentication codes, can make it challenging to verify the integrity and authenticity of the encrypted data. This opens the door for potential data tampering or unauthorized modifications, posing a considerable security risk.
Scalability
Symmetric algorithms face challenges when it comes to scalability. Since each pair of communicating entities requires a unique shared key, the number of required keys increases exponentially with the number of participants. This can be impractical for large-scale networks or systems that involve numerous users, as managing a vast number of keys becomes complex and resource-intensive.
Lack of perfect forward secrecy
Symmetric algorithms lack perfect forward secrecy, meaning that if the shared key is compromised, all previous and future communications encrypted with that key become vulnerable. This limitation makes symmetric algorithms less suitable for scenarios where long-term confidentiality of data is crucial, such as secure messaging applications.
An in-depth analysis of symmetric algorithms
Symmetric algorithms, including the widely adopted AES, DES, and Blowfish, are favored for their speed and efficiency. However, their robustness is largely dependent on the size of the key and the security of the key during transmission and storage. While larger keys can enhance security, they also increase the computational load. Thus, selecting the appropriate key size is a critical decision that requires a careful balance between security and performance requirements.
One of the standout strengths of symmetric encryption is its application in bulk data encryption. Because of their speed, symmetric algorithms are ideally suited for scenarios where large amounts of data need to be encrypted quickly. However, they may not always be the best solution. In many cases, asymmetric encryption algorithms, despite their higher computational demands, are preferred because of their additional security benefits.
It's also crucial to note that cryptographic needs often go beyond just encryption and decryption. Other security aspects, such as data integrity, authentication, and non-repudiation, are not inherently provided by symmetric algorithms. Therefore, a comprehensive security scheme often uses symmetric algorithms in conjunction with other cryptographic mechanisms, such as hash functions and digital signatures, to provide a full suite of security services.
Final thoughts
Symmetric algorithms occupy a pivotal place in the realm of cryptography. Their efficiency and speed make them an invaluable asset for many applications, especially those involving large-scale data encryption. However, the limitations inherent in symmetric algorithms, including key management complexities, lack of authentication, and absence of perfect forward secrecy, necessitate meticulous implementation and the incorporation of additional security measures. Therefore, the decision to utilize symmetric algorithms should be made based on a thorough understanding of these pros and cons, as well as the specific requirements of the system in question.