How SHA-256 works
If you've heard of ‘SHA’ in various forms but aren't sure what it stands for or why it's essential — you’re in luck! We'll attempt to shed some light on the family of cryptographic hash algorithms today.
But, before we get into SHA, let's go over what a hash function is and how it works. Before you can comprehend what SHA-1 and SHA-2 are, you must first grasp these principles.
Let's get started.
What Is a Hash Function?
A hash function relates to a set of characters (known as a key) of a certain length. The hash value is a representation of the original string of characters, however, it is usually smaller.
Because the shorter hash value is simpler to search for than the lengthier text, hashing is used for indexing and finding things in databases. Encryption employs hashing as well.
SHA-1, SHA-2, SHA-256… What’s this all about?
There are three types of secure hash algorithms: SHA-1, SHA-2, and SHA-256. The initial iteration of the algorithm was SHA-1, which was followed by SHA-2, an updated and better version of the first. The SHA-2 method produces a plethora of bit-length variables, which are referred to as SHA-256. Simply put, if you see “SHA-2,” “SHA-256” or “SHA-256 bit,” those names are referring to the same thing.
The NIST's Formal Acceptance
FIPS 180-4, published by the National Institute of Standards and Technology, officially defines the SHA-256 standard. Moreover, a set of test vectors is included with standardization and formalization to confirm that developers have correctly implemented the method.
Let’s break down the algorithm and how it works:
1. Append padding bits
The first step in our hashing process is to add bits to our original message to make it the same length as the standard length needed for the hash function. To accomplish so, we begin by adding a few details to the message we already have. The amount of bits we add is determined so that the message's length is precisely 64 bits less than a multiple of 512 after these bits are added. This can be expressed mathematically in the following way:
n x 512 = M + P + 64
M is the original message's length.
P stands for padded bits.
2. Append length bits
Now that we've added our padding bits to the original message, we can go ahead and add our length bits, which are equal to 64 bits, to make the whole message an exact multiple of 512.
We know we need to add 64 extra bits, so we'll compute them by multiplying the modulo of the original message (the one without the padding) by 232. We add those lengths to the padded bits in the message and get the complete message block, which must be a multiple of 512.
3. Initialize the buffers
We now have our message block, on which we will begin our calculations in order to determine the final hash. Before we get started, I want to point out that we'll need certain default settings to get started with the steps we'll be taking.
a = 0x6a09e667b = 0xbb67ae85c = 0x3c6ef372d = 0xa54ff53ae = 0x510e527ff = 0x9b05688cg = 0x1f83d9abh = 0x5be0cd19
Keep these principles in the back of your mind for now; all will fit together in the following phase. There are a further 64 variables to remember, which will operate as keys and are symbolized by the letter 'k.'
Let's go on to the portion where we calculate the hash using these data.
4. Compression Function
As a result, here is where the majority of the hashing algorithm is found. The whole message block, which is 'n x 512' bits long, is broken into 'n' chunks of 512 bits, each of which is then put through 64 rounds of operations, with the result being provided as input for the next round of operations.
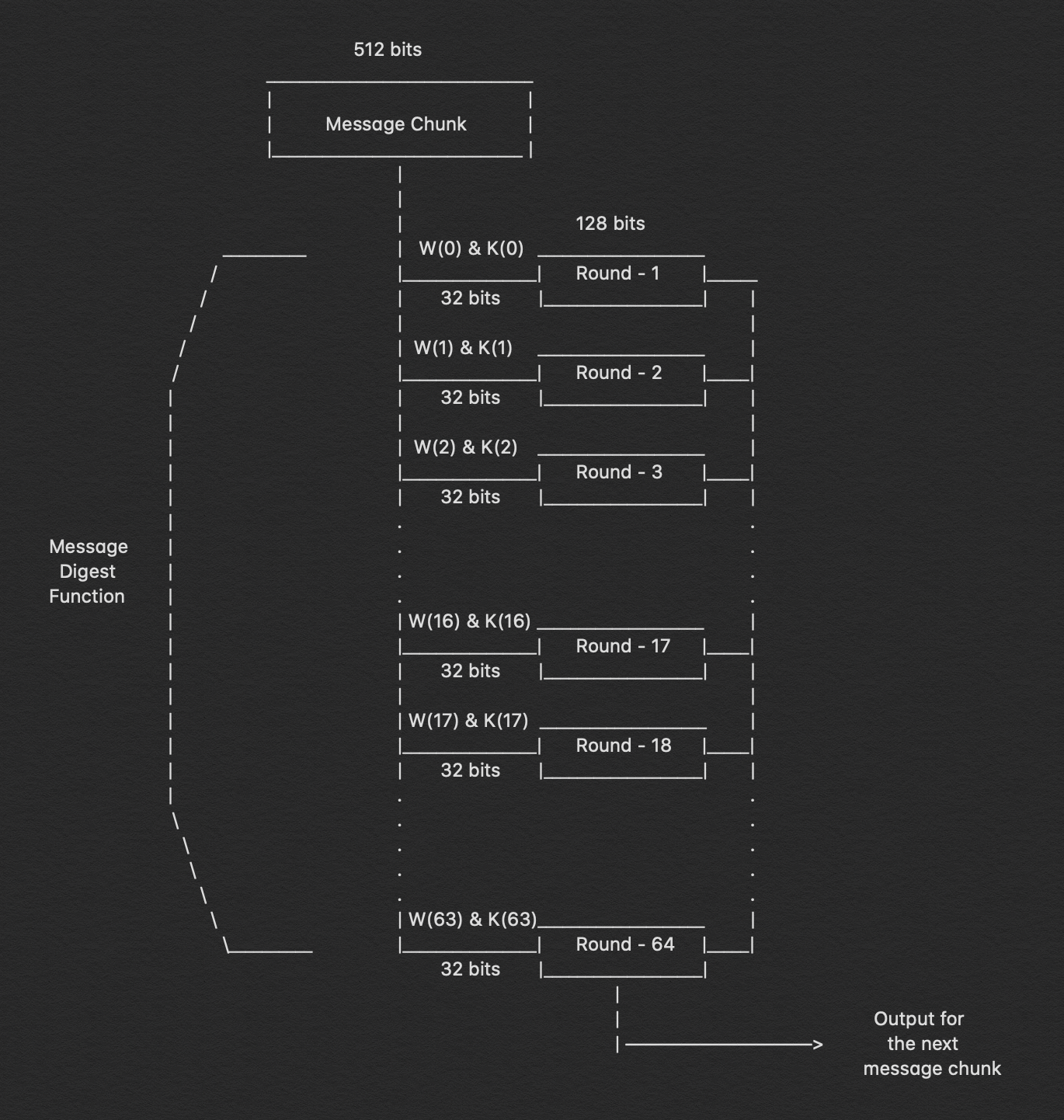
The 64 rounds of operation conducted on a 512-bit message are plainly visible in the figure above. We can see that we send in two inputs: W(i) and K(i). During the first 16 rounds, we further break down the 512-bit message into 16 pieces, each consisting of 32 bits. Indeed, we must compute the value for W(i) at each step.
W(i) = Wⁱ⁻¹⁶ + σ⁰ + Wⁱ⁻⁷ + σ¹where,σ⁰ = (Wⁱ⁻¹⁵ ROTR⁷(x)) XOR (Wⁱ⁻¹⁵ ROTR¹⁸(x)) XOR (Wⁱ⁻¹⁵ SHR³(x))σ¹ = (Wⁱ⁻² ROTR¹⁷(x)) XOR (Wⁱ⁻² ROTR¹⁹(x)) XOR (Wⁱ⁻² SHR¹⁰(x))ROTRⁿ(x) = Circular right rotation of 'x' by 'n' bitsSHRⁿ(x) = Circular right shift of 'x' by 'n' bits
5. Output
Every round's output is used as an input for the next round, and so on until just the final bits of the message are left, at which point the result of the last round for the nth portion of the message block will give us the result, i.e. the hash for the whole message. The output has a length of 256 bits.
Conclusion
In a nutshell, the whole principle behind SHA would sound something like this:
We determine the length of the message to be hashed, then add a few bits to it, beginning with '1' and continuing with '0' and then ‘1’ again until the message length is precisely 64 bits less than a multiple of 512. By multiplying the modulo of the original message by 232, we may add the remaining 64 bits. The complete message block may be represented as 'n x 512' bits after the remaining bits are added. Now, we split each of these 512 bits into 16 pieces, each of 32 bits, using the compression function, which consists of 64 rounds of operations. For the first 16 rounds, these 16 sections, each of 32 bits, operate as input, and for the next 48 rounds, we have a technique to compute the W(i). We also include preset buffer settings and 'k' values for each of the 64 rounds. We can now begin computing hashes since we have all of the necessary numbers and formulae. The hashing procedure is then repeated 64 times, with the result of the i round serving as the input for the i+1 round. As a result, the output of the 64th operation of the nth round will be the output, which is the hash of the whole message.
The SHA-256 hashing algorithm is now one of the most extensively used hashing algorithms since it has yet to be cracked and the hashes are generated rapidly when compared to other safe hashes such as the SHA-512. It is well-established, but the industry is working to gradually transition to SHA-512, which is more secure, since experts believe SHA-256 may become susceptible to hacking in the near future.
